Venn diagrams for genes
One of the easiest ways to compare datasets is to identify common elements between them and show the overlaps in a venn diagram.
 So when you're working with many data points such as thousands of genes, what is the best/fastest way to do it?
So when you're working with many data points such as thousands of genes, what is the best/fastest way to do it?
Venny - Intersect up to 4 lists and count the overlaps. See and download the overlaps between gene lists. Easy to use. Basic graphical output with overlaps not to scale and basic colours.
 Gene Venn - Intersect 2 or 3 lists. Overlap output in one text file. Overlaps not to scale, but graphics are somewhat more attractive than Venny.
Gene Venn - Intersect 2 or 3 lists. Overlap output in one text file. Overlaps not to scale, but graphics are somewhat more attractive than Venny.

BioVenn - Intersect 2 or 3 lists. High quality graphics in a range of formats (SVG/PNG), with extensive customisation which makes it perfect for publications. Overlaps are to scale. Optionally can map gene IDs to actual RefSeq/Ensembl/Affy accession numbers.

Venn SuperSelector - Intersect as many lists as you like. The output will be a matrix and the number of entries in the overlap. The first matrix is the pair-wise overlaps and then the 3-some overlaps and so on.

If you were to do this regularly in an automated fashion, then consider programming it in R (tutorial). If you just need the numbers of overlaps, you can try using the UNIX uniq command to find the duplicated values.

Venny - Intersect up to 4 lists and count the overlaps. See and download the overlaps between gene lists. Easy to use. Basic graphical output with overlaps not to scale and basic colours.

BioVenn - Intersect 2 or 3 lists. High quality graphics in a range of formats (SVG/PNG), with extensive customisation which makes it perfect for publications. Overlaps are to scale. Optionally can map gene IDs to actual RefSeq/Ensembl/Affy accession numbers.

Venn SuperSelector - Intersect as many lists as you like. The output will be a matrix and the number of entries in the overlap. The first matrix is the pair-wise overlaps and then the 3-some overlaps and so on.
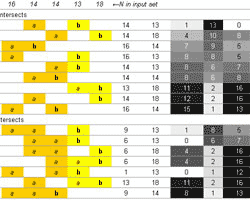
If you were to do this regularly in an automated fashion, then consider programming it in R (tutorial). If you just need the numbers of overlaps, you can try using the UNIX uniq command to find the duplicated values.
cat list1 list2 | sort | uniq -dWhich works, but UNIX comm command is a bit more sophisticated, outputting the common and distinct entries in a 3-field output.
comm list1 list2
